- Code de Huffman en C
- Partie 1 : Recherche bibliographique
- Partie 2 : Développement
- Partie 3 : Code source
I. Présentation générale de l’application
Le projet rendu tient compte de la totalité du cahier des charges du projet.
C’est à dire :
- Compression d’un fichier.
- Décompression d’un fichier.
- Compression d’un répertoire.
- Décompression d’un répertoire.
- Création des fichiers codage.dat et frequence.dat et du fichier TMP.
Dans la suite de cette partie nous aborderons comment marche le programme par étape sans entrer dans le détail ce chaque instruction. Pour ce genre de détails il est plus judicieux de consulter le code source qui comporte suffisamment de commentaires.
Il s’agit d’un programme MS-DOS. Un fois le programme lancé il faut choisir la fonction souhaitée dans le menu. La saisie des noms de fichiers se fait par chemin absolu. (par exemple : C:\Temp\fichier.txt).
Dans le cas d’une compression d’un répertoire le chemin doit être saisi sans le \ final. Pour le répertoire Temp à la racine on tapera C:\Temp. L’archive ainsi que les fichiers créés seront eux placés dans le répertoire parent c’est à dire C:\.
L’archive obtenue est placée dans le répertoire du fichier s’il s’agit de la compression d’un fichier et dans le répertoire parent s’il s’agit de la compression d’un répertoire. Les données à l’intérieur de l’en-tête sont organisées de la manière suivante :
Pour un fichier simple:
| Nb de fichiers (2) | Caractère (1) | Occurrence du caractère (4) | ‘\0’ (1) | |
| Taille du fichier original (4) | FICHIER TMP | |||
Pour la compression des répertoires :
| Nb de fichiers (2) | Caractère (1) | Occurrence du caractère (4) | ‘\0’ (1) | |
| Nom du fichier1 | ‘\n’ (1) | Taille du fichier1 original (4) | FICHIER1 TMP | |
| Nom du fichier2 | ‘\n’ (1) | Taille du fichier2 original (4) | FICHIER2 TMP | |
| Nom du fichier3 | ‘\n’ (1) | Taille du fichier3 original (4) | FICHIER3 TMP | |
Les chiffres entre parenthèses correspondent au nombre d’octets occupés par chaque champ.
II. Présentation de la méthode de Huffman
Une fois le fichier saisi par l’utilisateur, il est passé en argument d’une fonction qui renvoie un tableau contenant le nombre d’occurrences de chaque caractère dans le fichier.
Exemple pris sur les 6 premiers caractères d’un fichier quelconque :
Caractère |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
Occurrences |
0 |
2 |
5 |
3 |
0 |
6 |
3 |
Adresse |
200 |
300 |
400 |
600 |
700 |
L’arbre est constitué des structures de ce type :
typedef struct arbre_huff { unsigned char c; /* Caractère initial */ unsigned int occurence; /* Nombre d'occurrences dans le fichier */ int code; /* Codage dans l'arbre */ int bits; /* Nombre de bits sur lesquels est codée le caractère */ struct arbre_huff *gauche, *droite; /* Lien vers les nœuds suivants */ }; |
Pour chaque caractère présent (c’est à dire quand l’occurrence n’est pas nulle) dans le fichier on crée dynamiquement une feuille de l’arbre initialisée comme suit :
arbre = malloc(sizeof(*arbre)); |
On obtient un pointeur vers une variable structurée arbre. On remplit la variable de la manière suivante :
arbre->c=(char)i; /* Cast explicite */ arbre->gauche=NULL; /* Il s'agit des feuilles */ arbre->droite=NULL; /* Il s'agit des feuilles */ arbre->occurence = arbreN[i]; |
Pour l’instant seuls les champs c et occurrence sont remplis. Comme il s’agit des extrémités de l’arbre les pointeurs vers les fils sont à NULL.
Dans un tableau d’adresse de structure arbre_huff, les structures créées sont triées par ordre croissant d’occurrences. Cette opération est réalisée par la fonction :
void ajouter_temp_huff(struct temp_huff *tmp, struct arbre_huff *arbre) |
Les nœuds sont parcourus jusqu’à trouver le premier ayant une occurrence plus forte. Un fois trouvé le nouveau nœud est inséré juste après.
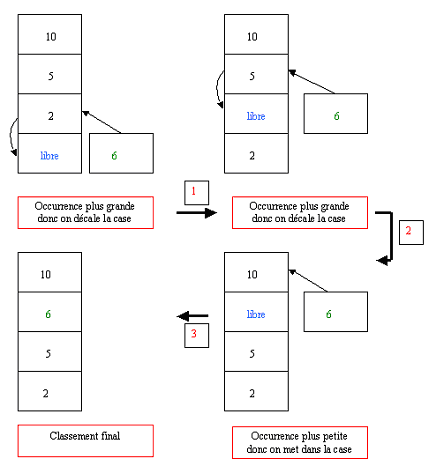
A la fin de la création des feuilles le tableau comportera les informations suivantes :
Indice |
0 |
1 |
2 |
3 |
4 |
Adresse |
600 |
300 |
400 |
700 |
200 |
Caractère |
5 |
2 |
3 |
6 |
1 |
Occurrence |
6 |
5 |
3 |
3 |
2 |
Gauche |
NULL |
NULL |
NULL |
NULL |
NULL |
Droit |
NULL |
NULL |
NULL |
NULL |
NULL |
Une fois ce tableau remplit on crée une nouvelle variable structurée dont le fils GAUCHE sera la structure ayant la plus faible occurrence et le fils DROIT sera l’avant-dernière plus petite occurrence. La fonction ajouter_temp_huff est rappelée. On a maintenant le tableau suivant :
Indice |
0 |
1 |
2 |
3 |
Adresse |
600 |
300 |
333 |
400 |
Caractère |
5 |
2 |
### |
3 |
Occurrence |
6 |
5 |
5 |
3 |
Gauche |
NULL |
NULL |
200 |
NULL |
Droit |
NULL |
NULL |
700 |
NULL |
On recommence cette opération jusqu’à avoir plus qu’un seul élément dans le tableau. Il s’agira de la racine de l’arbre avec dans le champ occurrence la somme de tous les caractères présents dans le fichier. En mémoire on se retrouve avec un arbre de cette allure :

Légende :
| Caractère | |
| Nb occurrences | |
| Gauche | Droit |
N = NULL
Le champ caractère des nœuds de l’arbre est rempli avec ce qui se trouvait dans la case au moment de la création. Ces données sont sans importance. Les adresses des structures en mémoires ont était choisies aléatoirement.
III. Description de l’arbre binaire d’encodage
Un fois l’arbre terminé on dispose d’un pointeur (*arbre) vers une structure de type arbre_huff. Il s’agit de la racine de l’arbre. Afin d’attribuer un code binaire à chaque caractère il faut parcourir l’arbre précédemment créé en notant le chemin de la racine jusqu’aux feuilles en rajoutant chaque fois un 0 ou un 1. Partir des feuilles entraînerait une confusion lors du décodage. Pour cela nous avons utilisé une fonction récursive.
Problème rencontré : Le langage C ne permet pas de gérer directement les bits. La plus petite unité étant l’octet. Il est impossible d’avoir le code directement en binaire.
Solution employée : Afin de pouvoir créer le fichier codage.dat nous avons crée une structure qui en plus du codage de Huffman contenait le nombres de bits significatifs (c’est à dire la profondeur du caractère dans l’arbre). Nous nous sommes servis d’une structure dictionnaire définie comme suit :
typedef struct dictionaire { int code; /* Codage de Huffman du caractère */ unsigned int bits; /* Nombre de bits significatifs du codage */ }; void creer_code(struct arbre_huff *arbre, int code, int niveau, struct dictionaire dico[]) { /* Condition d'arrêt de la fonction récursive : si on est sur une feuille */ if((arbre->gauche==NULL) && (arbre->droite==NULL)) /* Si c’est une feuille */ { arbre->code=code; /* Remplissage du champ correspondant */ arbre->bits=niveau; /* Correspond à la profondeur dans l’arbre */ /* Création du dictionnaire */ dico[arbre->c].code=code; dico[arbre->c].bits=niveau; return; } /* On part sur la droite */ if (arbre->droite!=NULL) creer_code(arbre->droite,(code<<1),niveau+1,dico); /* On ajoute 0 par la droite */ /* On part sur la gauche */ if (arbre->droite!=NULL) creer_code(arbre->gauche,(code<<1)+1,niveau+1,dico); /* On met 1 pour la gauche */ } |
Une fois cette fonction terminée la correspondance caractère <=> code de Huffman est sauvegardée dans un fichier <nom>-codage.dat. Dans cet exemple le codage obtenu est le suivant :
| 1 | 001 |
| 2 | 11 |
| 3 | 01 |
| 5 | 10 |
| 6 | 000 |
On remarque que plus les caractères sont utilisés et plus leur codage est court.
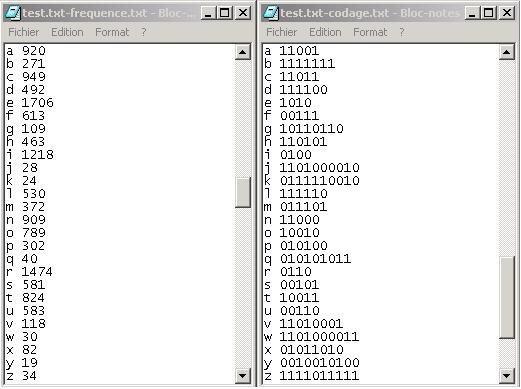
Les fichiers contenant les fréquences sont créés automatiquement à chaque exécution du programme. Une évolution permettant d’activer la production des fichiers à la demande est envisagée dans une future version.
IV. Présentation détaillée de la structure des programmes sources
Le programme est composé de deux fichiers source : huffman.c qui contient les instructions qui réalisent la compression et huffman.h dans lequel sont enregistrées les déclarations des constantes, la définition des structures et les prototypes des fonctions employées dans huffman.c.
Le programme s’articule autour de deux fonctions principales compression et décompression. Ces deux fonctions sont appelées directement par la fonction menu dans laquelle l’utilisateur entre son choix. Une fois à l’intérieur chaque fonction appelle d’autres fonctions ayant chacune une tâche précise.
#define MAX 256 : la compression se fait octet par octet. 256 est le nombre de valeurs différentes pouvant être codées sur un octet.
La compression s’organise de la façon suivante :
- copier_fichier : recopie le fichier que l’on veut compresser vers le répertoire C:\Temp\C\. Ne pas oublier de le créer avant.
- Compter_occ : renvoie un tableau contenant le nombre d’occurrences de chaque caractère dans les fichiers à compresser.
- Créer_freq : le tableau renvoyé par la fonction compter_occ est enregistré dans un fichier <nom>-frequence.txt.
- Créer_arbre : à partir du tableau d’occurrence construit l’arbre de Huffman. A la fin de cette fonction on dispose d’un pointeur vers la racine de l’arbre. Pour construire l’arbre cette fonction fait appel à 2 sous fonctions
- Ajouter_temp_huff : Tri les variables structurées en fonction du nombre présent dans leur champ occurrence.
- Nouveau_nœud : Récupère la variable structurée ayant la plus faible occurrence restante.
- Créer_code : Fonction récursive qui parcourt l’arbre de la racine jusqu’aux feuilles et relève le chemin pour y arriver. Cette fonction remplit également une structure dico qui permettra de visualiser les résultats de l’encodage.
- Ecrire_codage : Le fichier <nom>-codage.dat est crée. Il est rempli avec l’équivalence caractère ⇔ code de Huffman grâce à la structure dico passé en argument.
- Encodage : il s’agit de la fonction de compression. Elle parcourt le fichier à compresser, remplace chaque caractère par son code de Huffman, l’enregistre dans un buffer et une fois que le buffer est plein elle l’écrit dans l’archive.
- Ecrire_fichier : Enregistre l’en-tête puis enregistre la suite le fichier TMP précédemment créé. Cette fonction gérant à la fois les répertoires et les fichiers seuls elle est constituée de nombreuses conditions qui correspondent à chaque possibilité de compression.
- Suppr_arbre : l’arbre binaire de Huffman étant crée uniquement à l’aide de malloc, il faut le supprimer avant de quitter le programme afin de libérer la place qu’il occupe en mémoire. Cette fonction récursive parcours l’arbre et supprime ses extrémités.
La décompression réutilise une partie des fonctions mises en place à la compression.
- Lire_index : parcourt l’en-tête pour reconstituer le tableau des occurrences. Renvoie également le nombre de fichiers dans l’archive, cette information est utile uniquement pour les répertoires.
- Créer_arbre : même fonction que pour la compression. On est exactement dans les mêmes conditions c’est à dire un tableau d’occurrences. Le fait de lancer la même fonction conduit au même résultat à savoir l’arbre binaire du Huffman qui a servi à la compression.
- Creer_code : Pareil que pour la compression. Parcours l’arbre et associe un code binaire à chaque caractère. La différence est que cette fois nous utiliserons le code à l’envers.
- Extraire_nom : Reçoit le nom de l’archive et crée le chemin de décompression. Dans le cas d’un répertoire la boucle qui décompresse les fichiers les uns après les autres se situe ici. Ensuite cette fonction envoie ces informations à la fonction décodage.
- Decodage : Lit l’archive octet par octet puis parcours l’arbre bit à bit pour chercher le caractère correspondant. Si le caractère est trouvé, il est écrit dans le fichier original sinon un nouveau caractère est lu.
V. Aperçu du programme et mode d’emploi
1. Compression de fichier
Pour la compression du fichier simple il est nécessaire de saisir un chemin absolu. L’archive, le fichier fréquence et le fichier codage seront placés dans le même répertoire que le fichier compressé. La copie du fichier d’origine sera dans le répertoire C:\Temp\C\ et le fichier TMP sera dans le répertoire C:\Temp\. Il est nécessaire de créer ces répertoires avant l’exécution du programme.
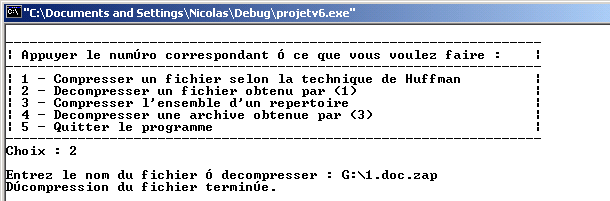
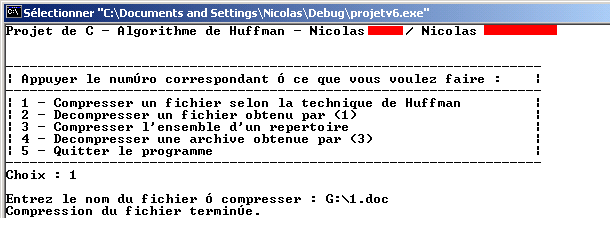 2. Décompression de fichier
2. Décompression de fichier
L’archive doit être placé dans le répertoire ou on souhaite décompresser.
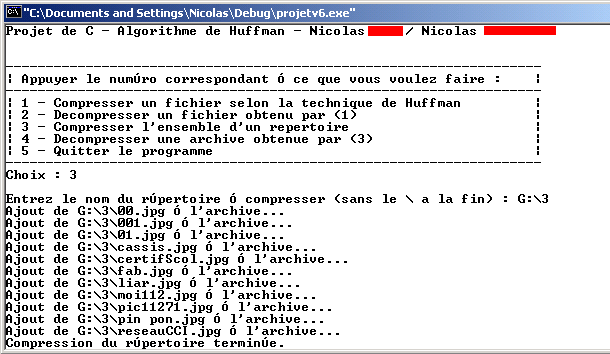
 3. Compression d’un répertoire
3. Compression d’un répertoire
A l’invite le nom du répertoire doit être saisi sans le \ à la fin. L’archive, le fichier fréquence et le fichier codage seront dans le répertoire parent. Le fichier TMP sera dans C:\Temp\ et les copies de tous les fichiers du répertoire sont dans le répertoire C:\Temp\C\. Ces répertoires doivent exister avant. Un fichier TMP sera créer par fichier du répertoire.
 4. Décompression d’un répertoire
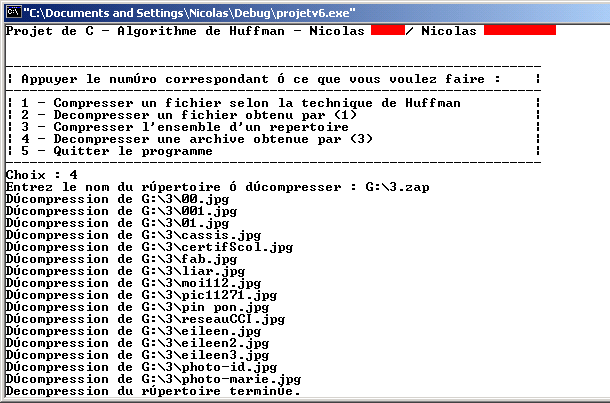
4. Décompression d’un répertoire
L’archive doit être placée dans le répertoire parent du répertoire dans lequel on souhaite décompresser les fichiers. Par exemple l’archive test.zap dans le répertoire C:\Huffman\ sera décompressée dans C:\Huffman\test\. Il est important d’avoir créer préalablement le répertoire C:\Huffman\test\.
Bonjour,
Merci pour le code source. Je voulais appliquer l’algorithme de Huffman mais sur des tableaux et non pas des fichiers donc je n’ai pas réussi à comprendre comment faire, et si je fais ces changements ça va marcher ou non !!
Merciiiii
Bonjour Sabrina,
Je ne comprends pas bien quelle est votre demande. Vous ne disposez pas de fichiers mais directement d’un tableau avec le nombre d’occurrences de chacun des caractères ? Dans ce cas, il suffit de passer la première étape de dénombrement et de charger directement l’arbre binaire avec le tableau dont vous disposez.
J’espère que ma réponse va vous permettre d’avancer.